Last year, I got into the Bertelsmann data science scholarship where, along with Python, Statistics, I also got to brush up my SQL skills. Time and again, I see myself searching for SQL cheatsheets whenever I forget something. So I decided to write all the tricks and tips into a blog for easy reference.
Basic SQL
Entity Relationship Diagram (ER Diagram) shows how data is structured and related in a database.
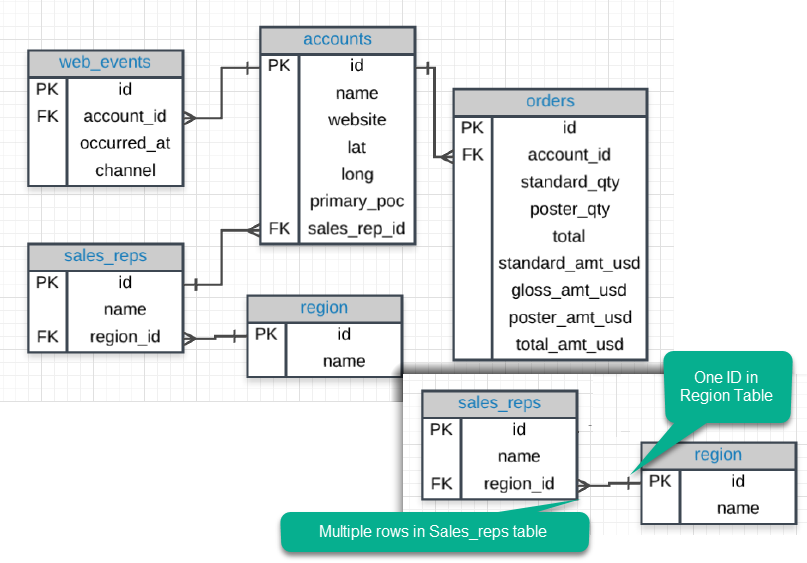 The “Crow’s foot” notation shows how columns in one table are related to the columns in other tables. There are several notations and “Crow’s foot” is one of those.
Businesses like relational databases because:
The “Crow’s foot” notation shows how columns in one table are related to the columns in other tables. There are several notations and “Crow’s foot” is one of those.
Businesses like relational databases because:
1. Data integrity is maintained: Referential integrity ensures that data doesn’t go missing or orphaned. Domain integrity ensures that the columns are within specified domains
2. Data Consistency: Multiple users can access data simultaneously and the data is same for everybody
3. Easy Access: SQL queries can be used to query data easily. Data can be stored in different tables and normalized to maintain integrity & consistency.
SQL is not case sensitive
If using a non-numeric data with an operator, must put the data in single quotes. Double quotes are for names of tables or fields. Sometimes You can omit them. The single quotes are for string constants.
select * from "employee" where "employee_name"='elina';
| Operators | Symbol |
|---|---|
| Equal to | = |
| Not equal to | <> or != |
| greater than, less than | >, < |
| greater than or equal, less than or equal | >=, <= |
Order of the columns listed in the ORDER BY clause matters. Columns will be ordered left to right.
| Statement | How to Use It | Other Details |
|---|---|---|
| SELECT | SELECT Col1, Col2, … | Provide the columns you want |
| FROM | FROM Table | Provide the table where the columns exist |
| LIMIT | LIMIT 10 | Limits number of rows returned |
| ORDER BY | ORDER BY Col | Orders table based on the column. ASC is the default |
| WHERE | WHERE Col > 5 | A conditional statement to filter your results |
| LIKE | WHERE Col LIKE ‘%me%’ | Only pulls rows where column has ‘me’ within the text |
| IN | WHERE Col IN (‘Y’, ‘N’) | A filter for only rows with column of ‘Y’ or ‘N’ |
| NOT | WHERE Col NOT IN (‘Y’, ‘N’) | NOT is frequently used with LIKE and IN |
| AND | WHERE Col1 > 5 AND Col2 < 3 | Filter rows where two or more conditions must be true |
| OR | WHERE Col1 > 5 OR Col2 < 3 | Filter rows where at least one condition must be true |
| BETWEEN | WHERE Col BETWEEN 3 AND 5 | Often easier syntax than using an AND |
SQL Joins
Database Normalization
Three questions are to be asked while normalizing tables:
1. Are the tables storing logical groupings of the data?
2. Can I make changes in a single location, rather than in many tables for the same information?
3. Can I access and manipulate data quickly & efficiently?
Joins
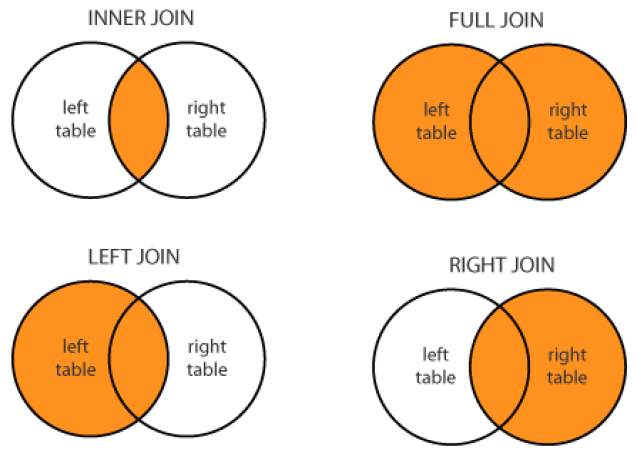 JOINS are useful for pulling data from multiple tables.
JOINS are useful for pulling data from multiple tables.
If you have two or more columns in your SELECT that have the same name such as accounts.name and sales_reps.name you need to alias them, else it will only show one of the columns.
INNER JOIN always pulls rows only if they exist as a match across two tables. Other JOINs pull rows that might only exist in one of the two tables. This will introduce a new data type called NULL. a full outer join will return the inner join result set, as well as any unmatched rows from either of the two tables being joined.
Left
Example:
SELECT w.channel, a.name, orders.order_id
FROM web_events AS w
JOIN accounts AS a
ON w.account_id=a.id
JOIN orders
ON orders.account_id = a.id
Below, first query results < second query results. > In 1st query, logic in WHERE clause happens after the join. In 2nd query, logic in ON clause filters the rows before the join.
SELECT *
FROM orders o
LEFT JOIN accounts a
ON o.account_id = a.id
WHERE a.sales_rep_id = 322
SELECT *
FROM orders o
LEFT JOIN accounts a
ON o.account_id = a.id
AND a.sales_rep_id = 322
SQL Aggregations
Count
-- Below Counts number of rows from accounts
SELECT COUNT(*)
-- Below counts the number of non-null id's
SELECT COUNT(accounts.id)
--Below counts the number of different id's
SELECT COUNT(DISTINCT accounts.id)
Sum
Unlike COUNT, you can only use SUM on numeric columns. It ignores NULL values
SELECT SUM(poster_qty) AS total_poster_sales
FROM orders;
SELECT SUM(standard_amt_usd)/SUM(standard_qty) AS standard_price_per_unit
FROM orders;
Min & Max
MIN and MAX can be used on non-numerical columns. Depending on the column type, MIN will return the lowest number, earliest date, or non-numerical value as early in the alphabet as possible. MAX does the opposite. They ignore NULL values.
SELECT MIN(occurred_at)
FROM orders;
SELECT MIN(name)
FROM region;
AVG
AVG returns the mean of the data (sum of all of the values in the column divided by the number of values in a column). It ignores NULL values in both numerator & denominator.
SELECT AVG(standard_qty) mean_standard
FROM orders;
GROUP BY
GROUP BY can be used to aggregate data within subsets of the data. You can GROUP BY multiple columns at once. Order of column names in GROUP BY clause doesn’t matter
GROUP BY always goes in between WHERE and ORDER BY. Any column in the SELECT statement that is not within an aggregator must be in the GROUP BY clause.
SELECT channel, COUNT(*)
FROM web_events
GROUP BY channel, account_id
ORDER BY channel, account_id
DISTINCT
Always used in SELECT statements. It provides unique rows for all columns written in the SELECT statement.
SELECT DISTINCT column1, column2, column3
FROM table1;
HAVING
Where clause doesn’t allow you to filter on aggregate columns. Instead, HAVING can be used.
This is only useful when grouping by one or more columns since if it’s an aggregation on the entire data set, output is one line and it’s not required to filter that.
HAVING is the “clean” way to filter a query that has been aggregated, but this is also commonly done using a subquery.
It appears after group by & before order by
SELECT s.id, s.name, COUNT(*) num_accounts
FROM accounts a JOIN sales_reps s
ON s.id = a.sales_rep_id
GROUP BY s.id, s.name
HAVING COUNT(*) > 5
ORDER BY num_accounts;
Also, you cannot filter on a calculated column using WHERE clause. You need to write the formula again For example: Below first query is wrong. The second one is correct. Similar format is to be used for filtering on aggregates with HAVING
SELECT MEMBER, CASE WHEN MEMID = 0 THEN GUESTCOST*SLOTS ELSE MEMBERCOST*SLOTS END AS COST FROM T1 WHERE COST > 30 -- Above query will return an error. Below format is correct. Instead, you can write everything inside a subquery & use SELECT* with a filter outside this subquery too! SELECT MEMBER, CASE WHEN MEMID = 0 THEN GUESTCOST*SLOTS ELSE MEMBERCOST*SLOTS END AS COST FROM T1 WHERE ((MEMID = 0 AND GUESTCOST*SLOTS > 30) OR (MEMID != 0 AND MEMBERCOST*SLOTS > 30) );
UNION
The union operator combines results from 2 SELECT statements into a single result set. Both the select statements should return same number of columns and respective columns should have same data type.
SELECT SURNAME
FROM CD.MEMBERS
UNION
SELECT NAME
FROM CD.FACILITIES;
DATE_TRUNC & DATE_PART
Format of dates in SQL: YYYY-MM-DD HH:MI:SS
DATE_TRUNC allows you to truncate your date to a particular precision. For example:
date_trunc('hour', timestamp '2001-02-16 20:38:40')
Will result in
2001-02-16 20:00:00
DATE_PART can be useful for pulling a specific portion of a date, but notice pulling month or day of the week means that the years may no longer be in order.
SELECT DATE_PART('year', occurred_at) ord_year, SUM(total_amt_usd) total_spent
FROM orders
GROUP BY 1
ORDER BY 2 DESC;
SELECT DATE_PART('dow', occurred_at) as day_of_week, SUM(total) as total_qty
FROM orders
GROUP BY 1
ORDER BY 2 DESC;
PGSQL automatically casts the date to its full timestamp in below example
select memid, surname, firstname, joindate
from cd.members
where joindate >= '2012-09-01';
CASE
CASE statement always goes in the SELECT clause.
CASE must include following components: WHEN, THEN, and END. ELSE is an optional component to catch cases that didn’t meet any other CASE conditions.
You can make a conditional statement using any conditional operator (like WHERE) between WHEN and THEN. This includes stringing together multiple conditional statements using AND and OR.
You can include multiple WHEN statements.
SELECT account_id,
CASE WHEN standard_qty = 0 OR standard_qty IS NULL
THEN 0
ELSE standard_amt_usd/standard_qty
END AS unit_price
FROM orders
LIMIT 10;
SELECT
CASE WHEN total>500 THEN 'Over 500'
ELSE '500 or under'
END AS total_group
COUNT(*) AS order_count
FROM orders
GROUP BY 1
p.s. Be wary of the apostrophe and always use the one present on English Keyboard
Some points to note
NULLs are different than a zero - they are cells where data does not exist. When identifying NULLs in a WHERE clause, we write IS NULL or IS NOT NULL. We don’t use =, because NULL isn’t considered a value in SQL. Also, it is not a good idea to represent unknown values using NULL “’ SELECT * FROM accounts WHERE primary_poc IS NULL “’ > Create Aliases when you create a new column by aggregating. For this alias, if you have 2 words, use “ ” instead of ‘ ‘. Ex: “First Name”.
Aggregators only aggregate vertically - the values of a column. If you want to perform a calculation across rows, you can do this with simple arithmetic
SQL evaluates the aggregations before the LIMIT clause.
SQL Subqueries & temporary tables
Both subqueries and table expressions are ways to write a query that creates a table, and then write a query that interacts with this newly created table.
Subqueries (inner queries/nested queries) are a tool for performing operations in multiple steps. Subquery is a query within a query. Subqueries that return a table (instead of a single value) are required to have aliases.
Inner query will run first & the outer query will run across the result set created by the inner query.
If the subquery is returning a single value, you might use that value in a logical statement like WHERE, HAVING, or even SELECT - the value could be nested within a CASE statement.
Most conditional logic will work with Subqueries returning a single value. IN is the only type of conditional logic that will work if Subquery returns multiple results.
You should not include an alias when you write a subquery in a conditional statement. This is because the subquery is treated as an individual value (or set of values in the IN) rather than as a table.
SELECT channel, AVG(events) AS average_events
FROM
(SELECT DATE_TRUNC('day', occurred_at) AS day, channel, COUNT(*) as events
FROM web_events
GROUP BY 1,2
) sub
GROUP BY channel
ORDER BY 2 DESC
SELECT SUM(total_amt_usd)
FROM orders
WHERE DATE_TRUNC('month', occurred_at) =
(SELECT DATE_TRUNC('month', MIN(occurred_at))
FROM orders
)
;
Sometimes, we can run subquery for each row of the main select statement. These are called correlated subqueries
SELECT distinct mems.name member,
(SELECT recs.name recommender
FROM members recs
WHERE mems.recommendedby = recs.memid
)
FROM members mems
ORDER BY member;
In above query, for every row, the subquery matches the recommender key with the member key. Ie, it uses information from the outer select statement.
Common Table Expression
WITH statement is often called a Common Table Expression or CTE. Subqueries can make your queries lengthy. CTEs can help break the query into separate “views” for better readability.
You can have as many CTEs as you want. They need to be defined at the beginning of query. Each CTE gets an alias.
If you have a CTE/subquery that takes a long time to run, you can run it separately & write it back to the DB as its own table.
WITH events AS
(
SELECT DATE_TRUNC('day', occurred_at) AS day, channel, COUNT(*) as events
FROM web_events
GROUP BY 1,2
)
SELECT channel, AVG(events) AS average_events
FROM events
GROUP BY channel
ORDER BY 2 DESC;
WITH table1 AS
(
SELECT *
FROM web_events
)
,
table2 AS
(
SELECT *
FROM accounts
)
SELECT *
FROM table1 JOIN table2
ON table1.account_id = table2.id;
SQL Data Cleaning
LEFT, RIGHT
pulls a specified number of characters for each row in a specified column starting at the beginning (from left)/end (from right).
LEFT(phone_number, 3)
RIGHT(phone_number, 8)
LENGTH
provides the number of characters for each row of a specified column.
LENGTH(phone_number)
POSITION/STRPOS
takes a character and a column, and provides the index where that character is for each row. > Index of the first position is 1 in SQL
POSITION(',' IN city_state).
STRPOS(city_state, ',').
Both POSITION and STRPOS are case sensitive, so looking for A is different than looking for a.
LOWER , UPPER
If you want to pull an index regardless of the case of a letter, you can use LOWER or UPPER to make all of the characters lower or uppercase.
SELECT POSITION('ST' IN UPPER('mystery'))
CONCAT, Piping ||
To combine columns together
CONCAT(first_name, ' ', last_name)
first_name || ' ' || last_name.
TO_DATE
TO_DATE function converts a string to a date. Following converts a month name into the number associated with that particular month.
TO_DATE(‘May’, 'month')
Result: 5
TO_DATE('2003/07/09', 'yyyy/mm/dd')
Result: date value of July 9, 2003
CAST
CAST is useful to change column types, like converting strings into numbers & dates. you can change a string to a date using CAST(date_column AS DATE). However, you might want to make other changes to your columns in terms of their data types. Get the string into the correct format first & use CAST to tell it’s in fact a date.
SELECT date orig_date,
CAST((SUBSTR(date, 7, 4) || '-' || LEFT(date, 2) || '-' || SUBSTR(date, 4, 2)) as DATE) new_date
FROM sf_crime_data
Casting with ::
instead of CAST(date_column AS DATE), you can also use date_column::DATE.
SELECT date orig_date,
(SUBSTR(date, 7, 4) || '-' || LEFT(date, 2) || '-' || SUBSTR(date, 4, 2))::DATE new_date
FROM sf_crime_data;
TRIM
can be used to remove characters from the beginning and end of a string. This can remove unwanted spaces at the beginning or end of a row that often happens with data being moved from Excel or other storage systems.
LEFT, RIGHT, and TRIM are all used to select only certain elements of strings, but using them to select elements of a number or date will treat them as strings for the purpose of the function. If you want to convert a number in to String perform any type of String operation on it.
COALESCE
COALESCE returns the first non-NULL value in a list. This can be used to replace the nulls.
SELECT COALESCE(NULL, NULL, NULL, 'W3Schools.com', NULL, 'Example.com');
Returns: W3Schools.com
SELECT * , COALESCE(primary_poc,’no_POC’) AS modified FROM accounts
Returns: primary_poc if it’s not null, else it will return ’no_POC’
SUBSTR
SUBSTR function extracts a substring from a string (starting at any position).
SUBSTR(string, start, length)
Grouping Sets
The ROLLUP operator can be used to produce a hierarchy of agrregations in the order passed to it.
Ex: ROLLUP(id, month) will output aggregations at these levels: (id, month), (id), ()
The CUBE operator will produce all possible hierarchies
EX: CUBE(id,month) will output at these levels: (id,month), (id), (month), ()
Window Functions
These functions operate on the result set of our query after all the aggregations & WHERE filtering is done.
Example:
select count(*) over(partition by date_trunc('month',joindate)),
name
from members
-- In above query, we are partitioning the data by month, counting the number of members per month and filling it in a new column 'count'. Instead, if we use below query
select count(*) over(partition by date_trunc('month',joindate) order by joindate)
-- In above, partition even splits it within a month, into further subdivisions per joindate and gives the order in which members joined, each month.
ORDER:
SELECT
FROM
WHERE
GROUP BY
Window Functions
HAVING
ORDER BY
LIMIT